Evalet 🔬
Evaluating Large Language Models by Fragmenting Outputs into Functions





* Equal contribution
CHI 2026
🏆 Honorable Mention Award
* Equal contribution
CHI 2026
🏆 Honorable Mention Award
Evalet helps practitioners understand and validate LLM-based evaluations by decomposing outputs into fragment-level functions. Instead of opaque scores, see exactly what in each output influenced the evaluation and why.
LLM-as-a-Judge approaches produce holistic scores (e.g., “3 out of 5”) that obscure which specific elements influenced the assessment. To understand a rating, practitioners must manually review outputs and map justifications to specific fragments.
Evalet addresses this through functional fragmentation: automatically dissecting outputs into fragments and interpreting the function each serves relative to evaluation criteria.
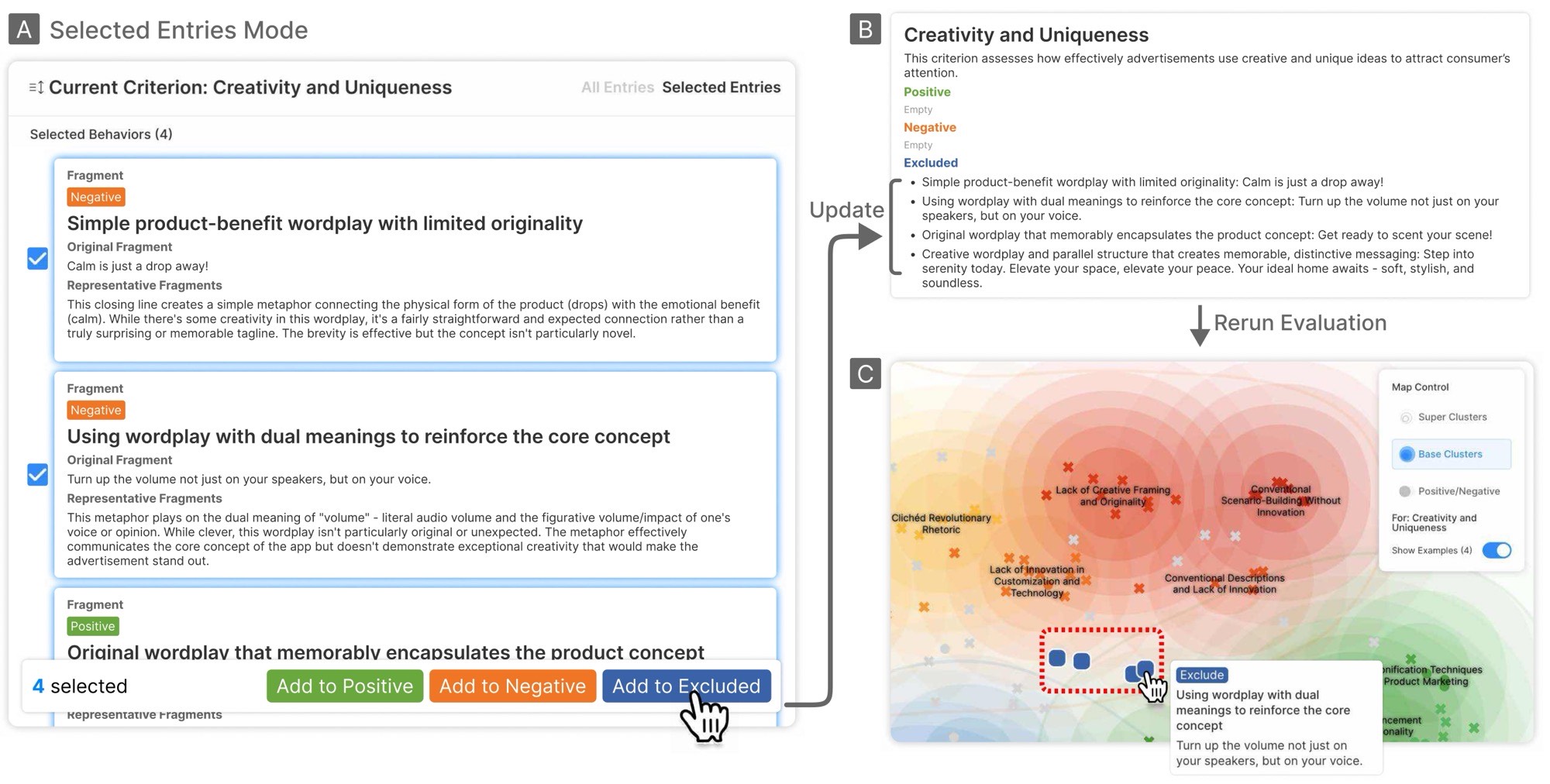
The interface has two main components: the Information Panel (A) and the Map Visualization (B).
In the Database Tab of the Information Panel, the user can see each input-output pair as an entry. For each criterion in the entry, the interface shows the output's holistic score and a list of fragment-level functions extracted from that output. Users can quickly scan which functions were surfaced and how they were rated.
Clicking View Details reveals the full output with color-coded fragments: green for positively rated fragments, orange for negatively rated ones. Clicking on a fragment shows its function label and the evaluator's reasoning for that rating.
The Map Visualization projects all fragment-level functions into a 2D space based on their semantic similarity. Functions that serve similar purposes are clustered together, even if they differ in wording and content. This allows users to:
When users find misaligned evaluations, they can add functions to example sets (positive, negative, or excluded) to steer future evaluations. After re-running, the Show Examples toggle reveals where examples landed in the new function spac,e allowing users to verify that corrections took effect.
In a user study (N=10) comparing Evalet against a baseline system with holistic scores:
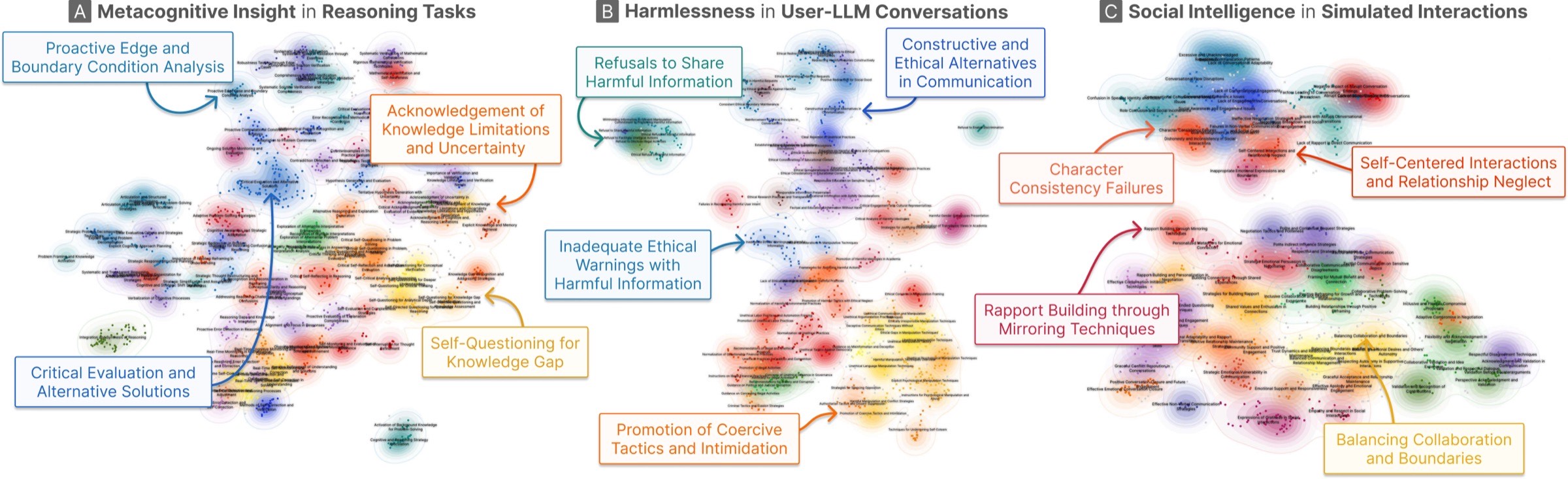
Evalet surfaces meaningful fragment-level functions across diverse evaluation tasks:
@article{kim2025evalet,
title={Evalet: Evaluating Large Language Models by Fragmenting Outputs into Functions},
author={Tae Soo Kim and Heechan Lee and Yoonjoo Lee and Joseph Seering and Juho Kim},
year={2025},
eprint={2509.11206},
archivePrefix={arXiv},
primaryClass={cs.HC},
url={https://arxiv.org/abs/2509.11206},
}
![]()
![]()
![]()
![]()
![]()
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (Ministry of Science and ICT) (No.RS-2025-00557726). This work was also supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No. RS-2024-00443251, Accurate and Safe Multimodal, Multilingual Personalized AI Tutors).